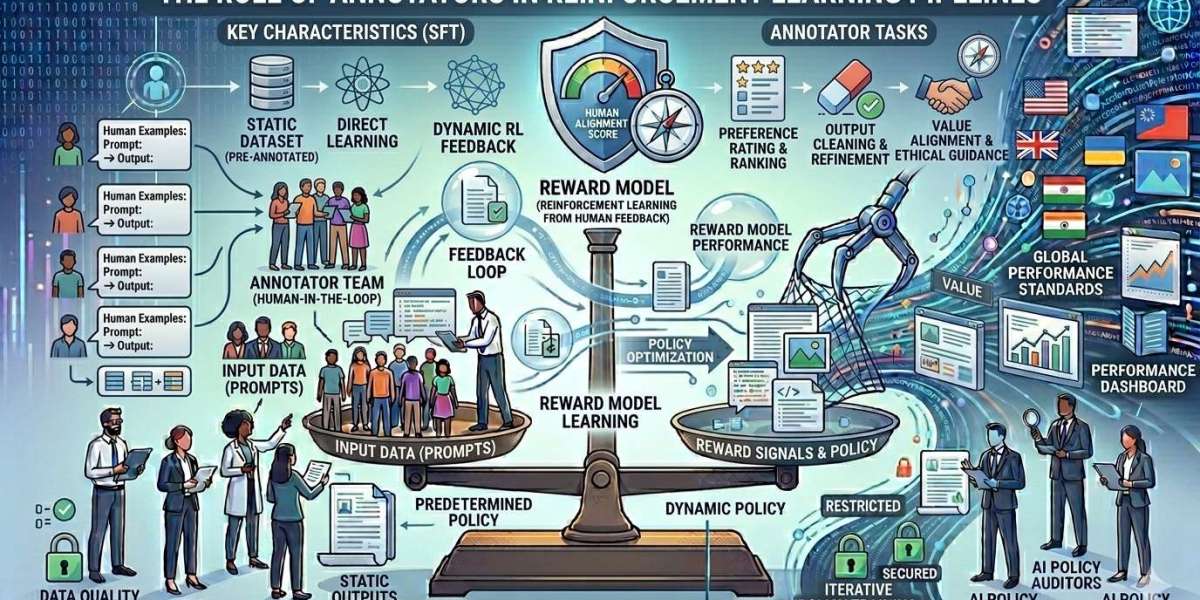
As artificial intelligence systems grow more sophisticated, the quality of human input behind them becomes increasingly critical. Reinforcement Learning (RL), particularly when applied to large language models (LLMs), relies heavily on human expertise to guide model behavior toward useful, safe, and aligned outcomes. At the heart of this process are annotators—skilled professionals who provide structured feedback that shapes how models learn from interactions.
At Annotera, we understand that annotators are not just contributors but core drivers of performance in reinforcement learning pipelines. Their role extends beyond simple labeling to include nuanced evaluation, judgment, and continuous refinement. In this article, we explore how annotators influence RL systems, why their contributions matter, and how organizations can leverage data annotation outsourcing to scale high-quality pipelines effectively.
Understanding Reinforcement Learning Pipelines
Reinforcement Learning is a framework where models learn by interacting with an environment and receiving feedback in the form of rewards or penalties. In the context of LLMs, this process is often operationalized through Reinforcement Learning with Human Feedback (RLHF).
Unlike supervised learning, where models learn from static labeled datasets, RL introduces a dynamic loop:
- The model generates outputs
- Annotators evaluate these outputs
- Feedback is converted into reward signals
- The model updates its behavior accordingly
This iterative process allows models to align more closely with human expectations over time. However, the effectiveness of this loop depends entirely on the quality and consistency of human feedback—making annotators indispensable.
Annotators as the Backbone of RLHF
In RLHF pipelines, annotators serve as human evaluators who bridge the gap between raw model outputs and meaningful reward signals. Their responsibilities are multifaceted and require both domain knowledge and structured decision-making.
1. Preference Ranking
One of the most common tasks in RLHF Annotation Services is ranking multiple model responses based on quality, relevance, and safety. Annotators compare outputs and determine which one better aligns with user intent.
This task may appear straightforward, but it requires careful judgment. Annotators must consider context, factual accuracy, tone, and adherence to guidelines. Poor ranking decisions can introduce noise into the reward model, ultimately degrading performance.
2. Quality Scoring and Evaluation
Beyond ranking, annotators often assign scores to model outputs based on predefined criteria such as:
- Helpfulness
- Accuracy
- Coherence
- Safety compliance
These scores help train reward models that guide reinforcement learning updates. Consistent scoring frameworks are essential to ensure that feedback is interpretable and actionable.
3. Safety and Policy Alignment
Modern AI systems must adhere to strict safety and ethical guidelines. Annotators play a key role in identifying:
- Harmful or biased outputs
- Policy violations
- Misleading or unsafe information
Their feedback ensures that reinforcement learning does not just optimize for correctness but also for responsible AI behavior. This is particularly critical in applications such as healthcare, finance, and customer support.
4. Edge Case Identification
Annotators often encounter edge cases—inputs or outputs that fall outside typical patterns. By flagging these cases, they help improve dataset coverage and robustness.
This function is especially valuable because RL systems can otherwise overfit to common scenarios, leaving them vulnerable to unexpected inputs.
How High-Quality Training Data Impacts LLM Performance
The phrase “garbage in, garbage out” is particularly relevant in reinforcement learning pipelines. High-quality annotation directly determines how effectively a model can learn from feedback.
When annotators provide consistent, accurate, and well-calibrated evaluations:
- Reward models become more reliable
- Training convergence improves
- Model outputs align better with user expectations
Conversely, inconsistent or low-quality annotations introduce ambiguity into the reward function, leading to unstable training and degraded performance.
At Annotera, we emphasize rigorous quality control processes, including:
- Multi-layer review systems
- Annotator calibration sessions
- Continuous feedback loops
These practices ensure that annotation quality remains high throughout the lifecycle of the project.
The Strategic Value of Data Annotation Outsourcing
Building an in-house annotation team for RL pipelines can be resource-intensive. It requires recruiting, training, managing, and continuously evaluating annotators across diverse domains. This is where data annotation outsourcing becomes a strategic advantage.
Partnering with a specialized data annotation company like Annotera offers several benefits:
Scalability
RL pipelines often require large volumes of annotated data, especially during iterative training cycles. Outsourcing enables organizations to scale annotation efforts quickly without compromising quality.
Domain Expertise
Different use cases require different expertise. Whether it’s legal text, medical content, or technical documentation, outsourced teams can provide domain-specific annotators trained for specialized tasks.
Cost Efficiency
Maintaining an in-house team involves significant overhead costs, including infrastructure, training, and management. Outsourcing allows companies to optimize costs while maintaining high standards.
Faster Turnaround
Dedicated annotation teams with established workflows can deliver results faster, accelerating the reinforcement learning cycle and reducing time-to-market.
Challenges in Annotation for Reinforcement Learning
Despite their importance, annotators face several challenges in RL pipelines:
Ambiguity in Guidelines
If annotation guidelines are not स्पष्ट and well-defined, annotators may interpret tasks differently, leading to inconsistent feedback.
Cognitive Load
Evaluating complex model outputs—especially in nuanced domains—can be mentally demanding. Fatigue can impact annotation quality if not managed properly.
Subjectivity
Certain tasks, such as preference ranking, inherently involve subjective judgment. Ensuring consistency across annotators requires robust calibration and monitoring.
Evolving Models
As models improve, annotation standards may need to evolve. Annotators must continuously adapt to new benchmarks and expectations.
Best Practices for Effective Annotation in RL Pipelines
To maximize the impact of annotators, organizations should adopt structured approaches:
Clear Annotation Guidelines
Provide detailed instructions with examples to reduce ambiguity and ensure consistency.
Continuous Training
Regular training sessions help annotators stay aligned with evolving project requirements.
Quality Assurance Mechanisms
Implement multi-level reviews, inter-annotator agreement checks, and performance tracking.
Feedback Loops
Encourage annotators to provide feedback on guidelines and workflows. This two-way communication improves both efficiency and quality.
Tooling and Infrastructure
Invest in annotation platforms that streamline workflows, reduce friction, and enable efficient data management.
The Future of Annotators in RL Pipelines
As AI systems become more advanced, the role of annotators will continue to evolve. We are already seeing trends such as:
- Increased use of hybrid human-AI annotation systems
- Greater emphasis on domain specialization
- Advanced tooling for annotation efficiency
- Integration of real-time feedback mechanisms
However, despite automation, human judgment will remain irreplaceable—especially for tasks involving nuance, ethics, and contextual understanding.
Conclusion
Annotators are the cornerstone of reinforcement learning pipelines, particularly in RLHF frameworks. Their ability to provide structured, high-quality feedback directly influences model performance, alignment, and safety.
For organizations aiming to build robust AI systems, investing in annotation quality is not optional—it is essential. By leveraging RLHF Annotation Services and partnering with an experienced data annotation company like Annotera, businesses can ensure that their reinforcement learning pipelines are both scalable and effective.
Ultimately, the success of reinforcement learning depends not just on algorithms, but on the humans guiding them. And in that equation, annotators are the decisive factor.