In today’s globalized digital world, communication across languages is more critical than ever. Businesses, researchers, and content creators depend on machine translation systems to bridge linguistic gaps efficiently. But what often goes unnoticed is the silent backbone that drives these systems — data annotation. Understanding how data annotation impacts machine translation accuracy reveals why high-quality labeled data is essential for improving translation performance and reliability.
What Is Data Annotation in Machine Translation?
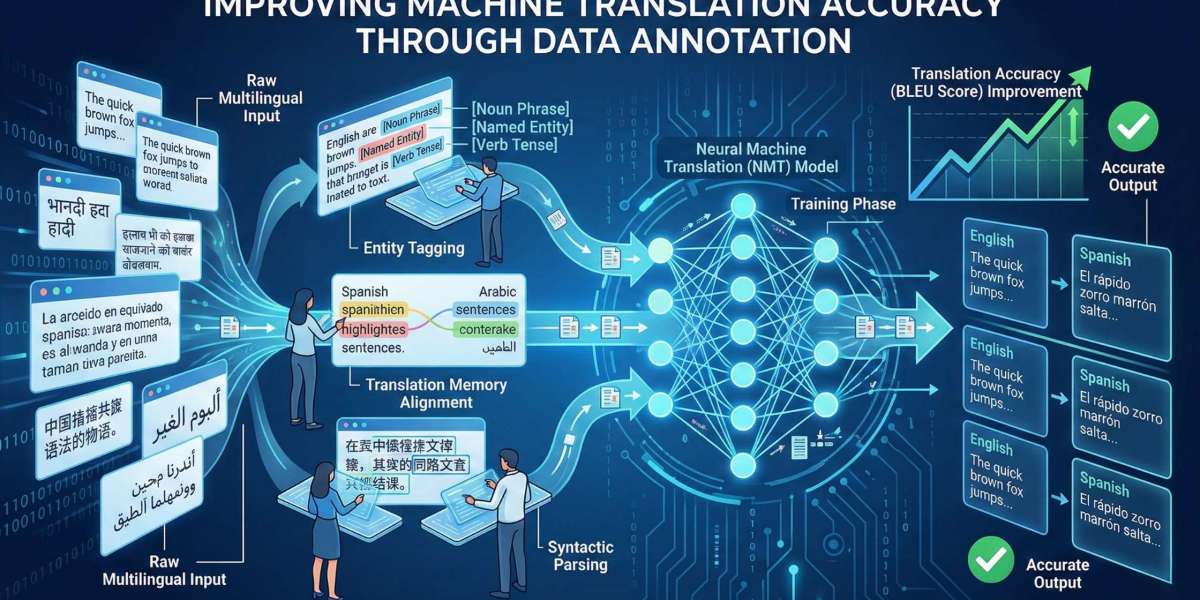
Data annotation is the process of labeling or tagging data to help AI and machine learning models understand context and meaning. In the realm of machine translation, this means tagging text with linguistic attributes such as parts of speech, syntax, named entities, and semantic relationships.
For example, annotating whether “bank” refers to a financial institution or a riverbank gives the model context to choose the right translation. Without accurate annotation, a model might translate words literally, missing the nuances of human language. That’s why how data annotation impacts machine translation accuracy is such a crucial consideration for AI developers and language service providers.
Why Data Quality Matters for Machine Translation Accuracy
The accuracy of any machine translation system is only as good as the data it’s trained on. Poorly annotated or inconsistent datasets can cause models to make frequent errors, particularly with idiomatic expressions, cultural references, or domain-specific jargon.
High-quality annotation helps models:
Recognize contextual clues in source and target languages.
Understand sentence structure and grammar patterns.
Differentiate between homonyms and polysemous words.
Adapt translations for specific industries like legal, medical, or technical content.
In short, clean, well-annotated data directly improves fluency, readability, and accuracy. This is the heart of how data annotation impacts machine translation accuracy — it ensures that machines learn from context-rich, relevant examples rather than random text.
The Role of Human Annotators and AI in Data Labeling
While automation tools can accelerate annotation, human expertise remains irreplaceable. Human annotators bring linguistic intuition and domain knowledge that machines lack. They understand subtle cultural nuances, tone variations, and idiomatic expressions — all of which heavily influence machine translation accuracy.
Many modern annotation workflows combine human judgment with AI-assisted tools. For instance, AI models pre-label large datasets, while human reviewers verify and correct annotations. This hybrid approach boosts both speed and quality, creating an optimal training foundation. When we analyze how data annotation impacts machine translation accuracy, it’s evident that human oversight is essential for producing trustworthy translations.
Common Challenges in Data Annotation for Machine Translation
Despite its importance, data annotation is complex and time-consuming. Some key challenges include:
Ambiguity in language: Words often have multiple meanings based on context.
Lack of domain expertise: Annotators unfamiliar with specialized topics (like law or medicine) may label data incorrectly.
Inconsistent labeling standards: Variations in annotation guidelines can lead to poor model generalization.
Scalability: Large datasets require substantial human and computational resources.
Overcoming these challenges is critical for anyone aiming to improve machine translation accuracy through better data practices.
How Accurate Annotation Boosts Machine Translation Performance
When annotation is done properly, the benefits are tangible:
Higher BLEU Scores: Models achieve better benchmark scores, indicating closer alignment with human translation.
Improved contextual accuracy: Translations become more natural and fluent.
Reduced bias: Balanced, diverse datasets minimize language bias.
Domain adaptability: Models trained on annotated domain-specific data perform better in specialized contexts.
Essentially, how data annotation impacts machine translation accuracy can be summarized in one sentence: the better your data labeling, the smarter and more reliable your translation engine becomes.
Conclusion
Understanding how data annotation impacts machine translation accuracy is vital for any organization that relies on AI-driven translation. Without precise annotation, even the most advanced neural models can fail to capture linguistic nuances or cultural context. Investing in high-quality data annotation not only refines translation accuracy but also builds user trust and efficiency across multilingual workflows.
At My Transcription Place, we specialize in data annotation and multilingual solutions that enhance machine translation accuracy for businesses worldwide. Whether you need annotated datasets, translation support, or AI training data, our expert team ensures linguistic precision at every step.
Partner with My Transcription Place today to experience the power of expertly annotated data — and see firsthand how data annotation impacts machine translation accuracy in transforming your global communication.