Large Language Models (LLMs) have transformed how enterprises interact with data, automate workflows, and deliver intelligent user experiences. However, one persistent challenge continues to limit their reliability—hallucinations. These occur when models generate plausible-sounding but factually incorrect or misleading outputs, often with high confidence.
For organizations deploying AI in high-stakes environments such as healthcare, finance, or legal services, hallucinations are not just technical flaws—they are business risks. Addressing them requires a systematic approach grounded in high-quality data and robust human feedback mechanisms. At Annotera, we believe that combining advanced data curation with RLHF Annotation Services is the most effective way to mitigate hallucinations and improve LLM performance.
Understanding the Root Causes of Hallucinations
Before solving hallucinations, it is essential to understand why they occur. LLMs are probabilistic systems trained to predict the next word in a sequence. This objective inherently encourages models to “guess” when uncertain, sometimes prioritizing fluency over factual correctness.
Several factors contribute to hallucinations:
- Noisy or low-quality training data
- Incomplete or biased datasets
- Lack of grounding in verified sources
- Incentive structures that reward confident outputs over accurate ones
In particular, poor data quality plays a central role. When models are trained on inaccurate or inconsistent datasets, they internalize these flaws and reproduce them during inference.
This is where the importance of data annotation outsourcing and structured data curation becomes evident.
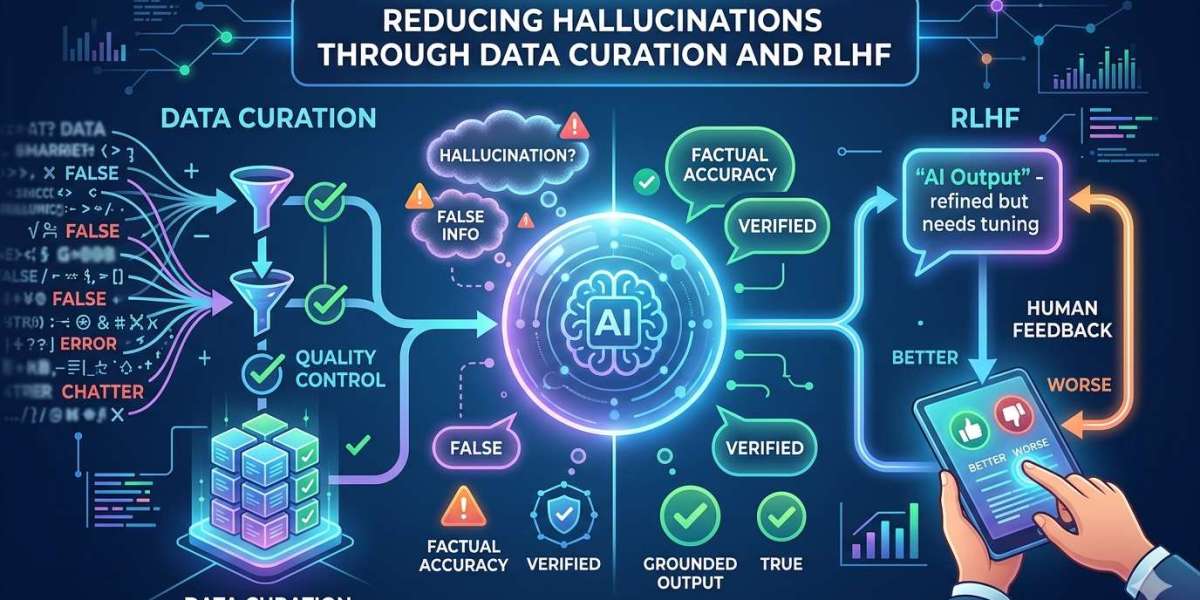
The Role of Data Curation in Reducing Hallucinations
Data curation is the first and most critical layer of defense against hallucinations. It involves collecting, filtering, validating, and structuring datasets to ensure accuracy, relevance, and completeness.
1. Eliminating Noise and Inconsistencies
High-quality datasets reduce ambiguity and prevent the model from learning incorrect associations. Fine-tuning on curated datasets minimizes exposure to irrelevant or biased information, directly lowering hallucination rates.
2. Ensuring Domain-Specific Accuracy
For enterprise applications, generic datasets are insufficient. Curated, domain-specific datasets—such as legal documents or medical literature—enable models to produce precise and contextually accurate outputs.
3. Structuring Data for Better Learning
Well-annotated datasets with clear labeling schemas improve the model’s ability to understand relationships between inputs and outputs. This structured learning reduces ambiguity and enhances factual grounding.
4. Teaching Models When Not to Answer
An often-overlooked aspect of data curation is including examples where the correct response is uncertainty (e.g., “I don’t know”). This trains models to avoid fabricating answers when information is insufficient.
At Annotera, as a leading data annotation company, we emphasize rigorous quality control pipelines, multi-layer validation, and domain-expert involvement to ensure that training data meets the highest standards.
RLHF: Aligning Models with Human Judgment
While data curation improves what models learn, Reinforcement Learning with Human Feedback (RLHF) refines how they behave.
RLHF introduces a feedback loop where human evaluators assess model outputs and guide the system toward preferred behaviors. This process transforms static models into adaptive systems that continuously improve.
How RLHF Works
- Human Evaluation – Annotators review model outputs for accuracy, relevance, and truthfulness.
- Preference Ranking – Responses are ranked based on quality.
- Reward Modeling – A reward function is trained to reflect human preferences.
- Policy Optimization – The model is fine-tuned to maximize the reward signal.
This iterative loop ensures that models learn not just to generate text, but to generate correct and trustworthy text.
Human feedback acts as a “compass,” guiding the model toward factual accuracy and discouraging hallucinations.
Combining Data Curation and RLHF for Maximum Impact
Individually, data curation and RLHF are powerful. Together, they create a comprehensive framework for hallucination reduction.
1. Pre-Training with Clean Data
The process begins with curated datasets that establish a strong foundational knowledge base.
2. Fine-Tuning with Task-Specific Data
Models are then fine-tuned on domain-specific datasets, ensuring contextual accuracy.
3. RLHF for Behavioral Alignment
Finally, RLHF aligns the model’s outputs with human expectations, correcting residual errors and reinforcing truthful behavior.
This layered approach addresses hallucinations at every stage of the LLM lifecycle—from data ingestion to output generation.
How High-Quality Training Data Impacts LLM Performance
The relationship between data quality and model performance is direct and measurable. High-quality training data improves:
- Factual accuracy
- Contextual relevance
- Consistency across responses
- User trust and reliability
Conversely, poor data quality amplifies hallucinations and reduces model credibility. Research consistently shows that hallucinations are closely tied to the quality and representativeness of training datasets.
For enterprises, this underscores the value of partnering with a specialized data annotation company that can deliver scalable, high-quality datasets.
The Business Case for Data Annotation Outsourcing
Building high-quality datasets and implementing RLHF pipelines requires significant expertise, infrastructure, and human resources. This is why many organizations turn to data annotation outsourcing.
Key Advantages
- Access to skilled annotators and domain experts
- Scalable data labeling operations
- Cost efficiency without compromising quality
- Faster turnaround times for model development
Outsourcing also enables companies to focus on core AI innovation while relying on specialized partners like Annotera for data-centric processes.
Best Practices for Reducing Hallucinations
To effectively minimize hallucinations, organizations should adopt the following strategies:
1. Invest in High-Quality Data Pipelines
Ensure datasets are clean, verified, and regularly updated.
2. Implement Multi-Level Quality Assurance
Use layered validation processes, including automated checks and human review.
3. Leverage RLHF Annotation Services
Continuously refine model outputs using structured human feedback loops.
4. Incorporate Negative Examples
Train models to recognize uncertainty and avoid overconfident guessing.
5. Monitor and Evaluate Outputs
Deploy ongoing evaluation frameworks to detect and correct hallucinations in production.
The Future of Hallucination Mitigation
While hallucinations cannot be completely eliminated, advancements in data curation and RLHF are significantly reducing their frequency and impact. Emerging approaches focus on:
- Better reward modeling techniques
- Fine-grained human feedback
- Hybrid systems combining retrieval and alignment
- Continuous learning pipelines
However, the foundation remains unchanged: high-quality data and human-guided alignment.
Conclusion
Reducing hallucinations in LLMs is not a single-step solution—it is a continuous process that requires precision, expertise, and iterative refinement. Data curation ensures that models learn from accurate and reliable information, while RLHF aligns their behavior with human expectations.
Together, these approaches form a powerful strategy for building trustworthy AI systems.
At Annotera, we specialize in delivering end-to-end solutions—from data annotation outsourcing to advanced RLHF Annotation Services—helping organizations unlock the full potential of LLMs while minimizing risks.
In an era where AI-driven decisions carry real-world consequences, investing in high-quality data and human feedback is not optional—it is essential.