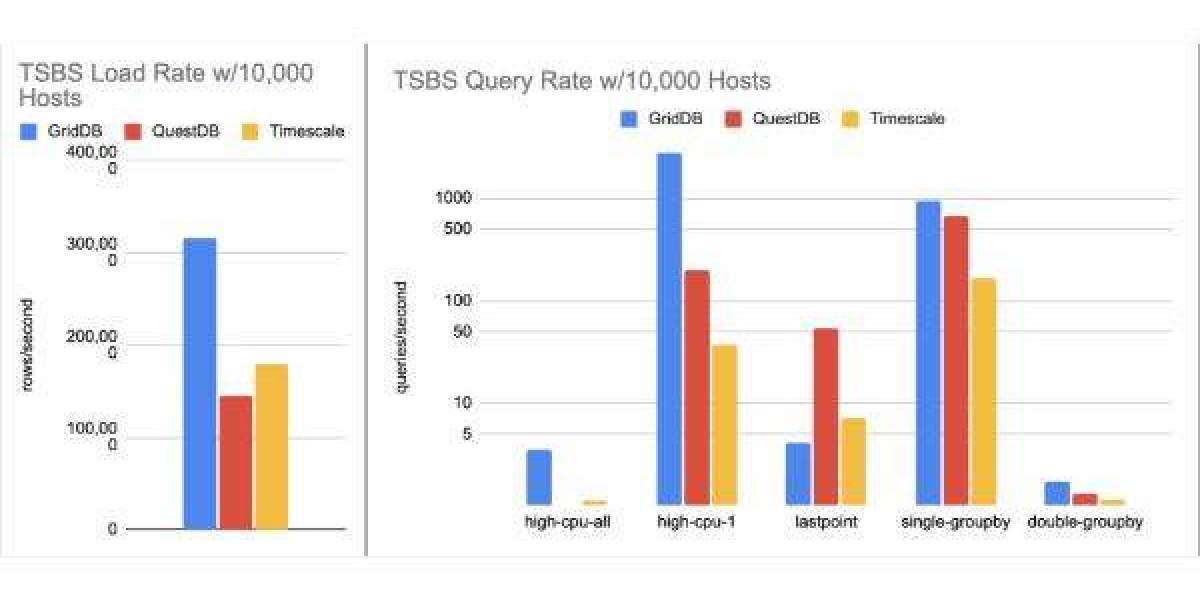
The global shift toward data-driven decision-making has placed an unprecedented emphasis on how we store and interpret information over time. As industries transition from reactive to proactive models, the infrastructure supporting them must evolve to handle trillions of data points with precision. Many technical architects are now turning to db engines tsdb to provide the foundational layer for high-frequency data ingestion and complex analytical processing. These systems ensure that every millisecond of operational history is preserved and accessible for immediate insight.
The Structural Superiority of Temporal Engines
Modern database architecture has branched into specialized niches to solve the limitations of traditional row-based storage. In a temporal engine, data is treated as a continuous flow rather than static entries. This approach allows for massive optimization in how data is written to the physical disk, minimizing overhead and maximizing the speed at which incoming streams can be captured.
By utilizing time-partitioned indexing, these databases can isolate specific windows of time during a query. This means that if an engineer needs to see the performance of a turbine during a specific hour last Tuesday, the system only scans the relevant data segment rather than the entire multi-terabyte dataset. This efficiency is what allows modern enterprises to maintain peak performance even as their data footprint expands exponentially.
Optimizing for High-Velocity Information
Handling high-velocity information requires more than just fast writes; it requires intelligent data lifecycle management. High-performance engines incorporate automated retention policies that manage data as it ages. Frequently accessed recent data can be kept on high-speed storage, while historical data is automatically compressed or moved to more cost-effective storage tiers without losing its queryability.
Furthermore, the implementation of sophisticated encoding techniques ensures that repetitive data—which is common in sensor readings—takes up minimal space. This not only reduces storage costs but also speeds up query performance, as there is physically less data to read from the disk during a scan. These optimizations are essential for any organization looking to scale their IoT or monitoring infrastructure.
Navigating the Global time series database ranking
Choosing a technology partner in this space involves understanding the current market dynamics and performance benchmarks. When reviewing the time series database ranking, it becomes evident that the most successful platforms are those that prioritize seamless scalability and high availability. The ability to add nodes to a cluster without downtime has become a non-negotiable requirement for mission-critical applications in finance and telecommunications.
As more companies move toward hybrid and multi-cloud environments, the ranking also reflects a preference for platforms that offer deployment flexibility. Systems that can run just as efficiently on a small edge device as they do in a massive cloud-based data center are quickly rising to the top. This versatility allows organizations to build a unified data strategy that spans from the factory floor to the executive boardroom.
Transforming Industrial Intelligence
In the realm of industrial automation, the ability to analyze temporal data in real-time is a competitive necessity. By integrating advanced storage engines into the production line, manufacturers can achieve a level of transparency previously thought impossible. Every sensor on every machine contributes to a holistic view of the production environment, allowing for the immediate detection of anomalies that could indicate a potential failure.
This level of intelligence extends to the supply chain as well. By tracking the environmental conditions of goods in transit—such as temperature and humidity—companies can ensure product quality and regulatory compliance. The database serves as the "source of truth," providing an immutable record of every condition the product encountered from the warehouse to the customer's doorstep.
Advanced Analytics and Resource Management
The true power of a dedicated storage engine is realized during the analytical phase. Beyond simple data retrieval, these platforms support complex mathematical operations and statistical modeling directly within the database. This "push-down" of logic reduces the need to move large volumes of data across the network to an external application, significantly decreasing the time to insight.
Resource management is also simplified through the use of native aggregation features. By pre-calculating summaries of data—such as hourly averages or daily peaks—the system can serve dashboard requests almost instantaneously. This ensures that even as the number of users and concurrent queries grows, the system remains responsive and efficient.
Strategic Depth and influxdb tsdb analyze
When organizations look to optimize their existing stacks, they often perform a deep dive to influxdb tsdb analyze how their current tools handle specific workloads. This analysis typically focuses on the "cardinality" of the data—the number of unique combinations of tags and metrics. Managing high cardinality is a primary differentiator among top-tier engines, as it determines whether a system will slow down as the number of tracked devices increases.
Modern solutions have introduced innovative indexing strategies to mitigate the performance impact of high cardinality. By using inverted indexes and bitmap structures, these databases can quickly filter through millions of unique series to find the exact data points required. This technical depth ensures that the database remains a robust asset even as the complexity of the underlying business grows.
The Intersection of Data and Connectivity
As the world becomes increasingly interconnected through 5G and satellite internet, the volume of data generated will only continue to rise. This creates a need for databases that can function in "disconnected" or "low-bandwidth" environments. The next generation of temporal engines will likely feature advanced synchronization capabilities, allowing edge nodes to collect data locally and sync with the central hub whenever a connection is established.
This connectivity also brings a renewed focus on security and data integrity. Modern platforms are incorporating native encryption and fine-grained access controls to ensure that sensitive industrial or financial data is protected at rest and in transit. As data becomes the lifeblood of the modern economy, the systems that store it must be as secure as they are fast.
Building a Resilient Data Strategy
A resilient data strategy starts with choosing the right foundation. By selecting a storage engine designed specifically for temporal data, organizations can avoid the "technical debt" that often comes with trying to force-fit time series workloads into general-purpose databases. This foresight allows for smoother scaling, lower operational costs, and faster development cycles.
Ultimately, the goal of any data infrastructure is to turn raw numbers into actionable wisdom. Whether it is predicting the next market trend or optimizing a power grid, the ability to store and analyze information in the context of time is the key to unlocking new levels of efficiency and innovation. The continued evolution of these specialized systems promises a future where data is not just stored, but truly understood.